|
3. BLAST
3-1.
알고리즘
BLAST는
FASTA와 마찬가지고 "Word Based Method"를 이용한다.
하지만 FASTA와는 달리
별도의 pre-formatted 검색 데이터베이스를 필요로 한다.
|
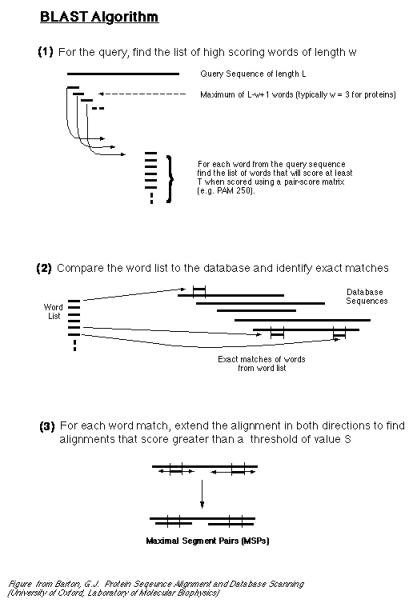
실제 유사성 검색 과정은 다음과 같다.
1) 우선
검색을 query 서열로부터 3개의 단백질 혹은 11개의 염기로 이루어진
단어들과 T 이상의 점수를 가지는 조합을 만든다. 만들어진 조합들을 각각 서열 데이터베이스의
서열들과 비교한다.
2) 만약
각각의 단어 조합들과 같은 서열이 서열
database에서 발견이 되면 BLAST는
옆 단어들로 유사성 검색을 확장 시켜 나간다.
이때 gap은 허용하지
않는다.
3) 확장을
마친 후 데이터베이스 서열 중 일정 값 이상의
HSP(High-scoring Segment Pairs)를
가진 서열들을 추출하고 이때 중복되지 않는 각각의 HSP들은 통계적인 test를
거쳐 연결한다.
3-2.
참고
사항
1) BLAST에서 기본적으로 제공하는 서열 데이터베이스(non-redundant, nr)에는 EST 데이터베이스가 포함되어 있지 않다.
2) BLAST는 query 서열과
gap 없이 일정 값 이상의 HSP를
기록하지 못하는 서열들을 미리 제거한다. 그래서
FASTA에 비해 훨씬 비교 속도가
빠르다. 하지만 두 서열이 특정 부분이 높은 일치성을 가지고 있지는
않지만 대부분의 서열에서 유사성을 가지고 있는 경우에는 BLAST가 검색을
해 낼 수 없다.
3) 또다른 BLAST의
단점은 잘 보존되어있으나 큰 의미가 없는 서열들의 부분에 민감하다는 것이다. 즉
short repeat sequence나 특정한 residue들이 많이 존재하는 서열 (GC 혹은 AT rich)들이
그 예가 될 수 있는데 이런 서열들을
query 서열로 이용하였을 경우
많은 중요하지 않은 서열들이 결과로 나오게 된다. 이런 결과들을 피하기 위해 BLAST는 filtering 하는
기능을 기본값으로 가지고 있다. 결국 repeat
sequence같은 것들은 검색하기
이전에 제거된다는 사실을 기억해야 한다.
4) FASTA와 마찬가지로
BLAST도 단백질 서열을 위해
개발된 프로그램이다. 염기 서열의 검색이 가능하지만 sensitivity가 떨어지므로
염기 서열로 염기 데이터베이스를 검색해 진화적으로 떨어져있는 서열을 찾고자 한다면 FASTA를
사용하는 게 낫다.
3-3. BLAST의 종류
blastp |
단백질 서열간의 비교 |
blastn |
염기 서열간의 비교 |
blastx |
입력한 염기 서열을 6개의 frame으로 변환 후 단백질 서열 데이터베이스와 비교 |
tblastn |
염기서열 database를 6 frame으로 변환 후 입력한 단백질 서열과 비교 |
tblastx |
입력한 염기 서열과 염기서열 database를 모두 6 frame으로 변환 후 비교 |
3-4. 검색 파라미터들
-H, HISTOGRAM: 검색 후 결과에 histogram을 포함여부를 결정하는 옵션으로 기본값은 포함한다.
-V, DESCRIPTIONS: 결과에서 보여주는 유사성을 가진 서열들의 갯수를 정한다. 기본값은 100개의 유사성을 가진 서열들에 대한 간단한 정보를 결과에서 보여준다.
-B, ALIGNMENT: 검색 결과 후 배열을 보여주는 서열들의 갯수로 기본값은 50개이다.
-E, EXPECT: 두 서열의 statistical significance threshold 값이다. 즉 어느 정도 이상의 값을 가져야 두 서열이 유사하다고 정의할 수 있는가에 대한 값을 정하는 옵션으로 기본값은 10이다. 이 값은 Karlin과 Altschul의 stochastic model에 의하면 10개의 서열의 일치는 우연히 일어날 수 있다고 정의한다..
-S, CUTOFF: high-scoring segment pair들의 cutoff를 정하는 옵션으로 기본값은 EXPECT value로부터 계산 된 값을 이용한다.
MATRIX: 유사성 검색에 이용되는 scoring matrix의 종류로 기본값은 BLOSUM62이다. BLASTP, BLASTX, TBLASTN, TBLASTX의 경우 옵션으로 PAM40, PAM120, PAM250, IDENTITY등의 matrix를 이용한다. 하지만 BLASTN의 경우에는 다른 MATRIX를 선택하실 수 없다.
STRAND: TBLASTN의 경우에는 top혹은 bottom strand 중 선택하여 검색을 할 수 있다. 그리고 BLASTN, BLASTX, TBLASTX의 경우에도 quary sequence중 top혹은 bottom strand의 open reading frame을 선택하여 검색할 수 있다.
FILTER: 통계적으로는 중요한 값을 가지지만 생물학적으로는 의미가 없는 서열들을 제거하는 옵션이다. Low compositional complexity를 가진 서열들은 Wootton과 Federhen에 의해 개발된 SEG program이 이용되고 internal repeat들은 Claverie와 States에 의해 개발된 XNU program 을 이용한다. BLASTN의 경우에는 Tatusov와 Lipman에 의해 개발된 DUST가 이용된다. 입력한 서열 중 일부가 low complexity sequence로 인식이 되면 blast는 염기의 경우 "N"으로 단백질의 경우 "X"로 표시한다. 그래서 실제 입력을 정확히 했음에도 불구하고 결과와 함께 출력되는 입력 서열에는 "NNNNNNN"혹은 "XXXXXXX"가 포함되어 있는 것을 가끔 볼 수 있다. 기본값은 filtering을 하는 program들을 이용하게 되어있고 사용자가 원하는 경우 filter를 선택하지 않을 수 있다. Filter의 기능은 오직 입력한 서열에 한해서만 적용된다.
NCBI-gi: accession number 와 locus name이외에도 gi 번호를 같이 보여줄 수 있는 옵션이다.
3-5.
BLAST의
결과
해석
기본적으로 결과의 형태는 FASTA의 결과 출력
형태와 유사하다. 결과는
P-value 순으로 보여준다. 일반적으로 가장 큰 의미를 가지는 값은 P-value와 High score이다. 의미가
있다고 생각되는 단백질 서열의 경우
P-value는 가능한 한 작아야
하고 High score는 커야 한다.
DNA의
경우 의미있는 서열의 P-value가
0.0001보다 작더라도 두 서열이
연관에 없을 가능성이 크다. High score보다
P-value가 서열의 길이에 대해 영향을 받지 않으므로 의미 있는 서열인지
판단할 때 더 중요한 기준이 된다. P-value가 e-100보다 작은 경우는 일반적으로 같은 종의
같은 서열로 고려된다. P-value가
e-50-e-100사이일 때는 아주 유사한 서열로 고려할 수 있다. P-value가 e-10-e-50사이일 때는 연관된 서열로 고려할 수 있다. P-value가
0.1-e-5사이일 때는 연관성을 가질 가능성은 있으나 상당히 먼 관계를
가지고 있을 가능성이 있다. 일반적으로 P-value가 0.1보다
큰 경우에는 큰 의미를 가진다고 할 수 없다.
3-6. BLAST 2.0
BLAST 2.0은 기존의 blast에
gap을 도입하는 기능이 추가되었다. 일반적으로 blast 검색을
수행하면 결과가 끊어진 몇 개의 조각들로 출력이 되는데, blast 2.0에서는 gap을
도입하여 FASTA와 같이 insertion과
deletion을 도입하여 상동성이
있는 조각들을 연결하여 결과를 보여준다.
그 이외의 옵션은 기본적인 blast의
옵션과 동일하고 다른 부분은 다음과 같다.
Graphical Overview : 결과에서 입력한 서열과 유사한 부분을 그림으로 표시해 주는 옵션이다.
Query Genetic Codes (blastx only) : blastx에서 translation을 할 때 어떤 genetic code를 사용하는 가를 선택할 수 있는 옵션이다.
BLAST2.0 검색 결과로는 'bit' score와 Expect value를 보여준다. 사용한 측정행렬에 따라 값이 달라지는 high score와는 달리 bit score는 측정 행렬의 영향을 받지 않는다. Expect value는 통계적인 의미가 있으며 특정 데이터베이스에서 우연히 (by chance) 해당 점수를 가지면서 배열될 수 있는 서열들의 갯수를 의미한다. 또 두 서열 사이의 expect value는 우연히 해당 점수를 가지며 배열하는 확률을 의미한다. 따라서 값이 작을 수록 서열은 더 의미가 있으며 검색 결과 서열들도 E-value가 작은 순서대로 나열한다. Expect value는 데이터베이스의 크기에 따라 바뀌며 (데이터베이스가 커질 수록 우연히 해당 점수의 배열을 할 서열의 수를 많아짐) 결과를 배열하는데 기준으로 삼기 좋은 값이며 같은 query로 다른 데이터베이스 검색 결과들을 비교할 때 사용할 수 있는 값이다.
3-7.
PSI-BLAST
또한
NCBI에서는 PSI(Position-Specific Iterated)-BLAST를 최근 개발하여 서비스하고 있다. PSI-BLAST는
일반 BLAST의 기능에 motif이나
profile의 비교 기능을 추가한
프로그램이다. 즉 PSI-BLAST는
기본적인 BLAST검색을 수행한 후 그 결과를 이용하여 multiple alignment를 수행한다. Multiple alignment를 통해 position-specific
score matrix를 제작하고 이 matrix를
이용하여 다시 BLAST 검색을 수행한다.
즉 일반 검색과 motif, profile검색을
동시에 수행하게 되는 것이다. 진화적으로 멀리 떨어져 있는 homolog 서열을
찾는데 유리하게 사용될 수 있다.